谈一谈在两个商业项目中使用MVI架构后的感悟
前言
MVI并非新兴事物,在2020年时亦曾有通过撰写一篇文章与诸位读者探讨一二的念头。
当时项目采用MVP分层设计,组员的代码风格差异也较大,代码中类职责赋予与封装风格各成一套,随着业务急速膨胀,代码越发混乱。试图用 MVI架构 + 单向流 形成 掣肘 带来一致风格。
但这种做法不够以人为本,最终采用 "在MVP的基础上进行了适当改造+设计约定的方式" 解决了问题,并未将MVI投入到商业项目中,于是 放弃了纸上谈兵。
在半年前终于有机会在商业项目中进行实践,同诸位谈一谈使用后的 个人感悟 ,并藉此讲透MVI等架构。
所有内容将按照以下要点展开:
- 从架构的理念出发 -- 简单列明各种
MVX的理念 , MVX:指代 MVC、MVP、MVVM、MVI - 拥抱复杂的同时实现简化 -- 通过对比理解单向数据流动所解决的痛点、设计Intent的原因等问题
- 单一可信数据源,不可僵化信奉
- 要想优雅,需要工具 -- 借助声明式、响应式编程工具,构建
流,屏蔽命令式编程中的细节,同样是聚焦和简化 - 状态和事件分家,绝不是吃饱了撑的 -- 为什么要裂变出状态和事件,如何界定
内容会很长,我会酌情再写一些 解 ,结合实例和代码演示内容。
两个项目的基本情况
相比于之前的巨型项目,这两个项目的业务量均不大,一个是基于蓝牙和局域网的操控类APP,下午简称APP-A,一个是内部使用的工具,分析公司各个产品的日志,简称APP-B。
虽然他们的业务深度要比一般的APP要深,但在 本质上一致 ,毕竟同类型业务量再多也仅仅是重复运用一套模式 ,并不影响本质。
和诸多项目的本质一致,均符合如下图所示的逻辑分层,并在人机交互过程中执行业务逻辑:
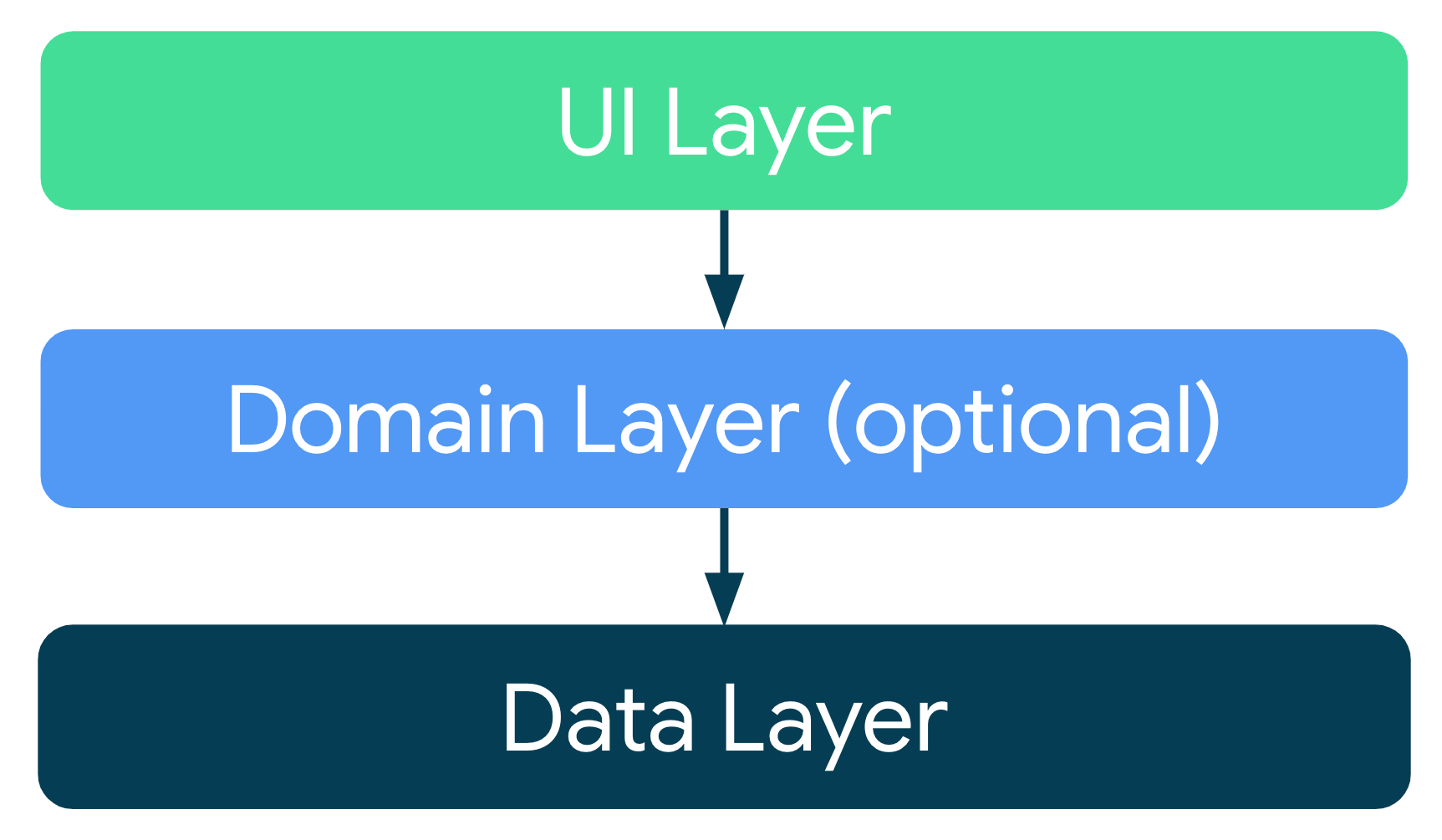
- APP-A 是Android项目,图方便纯kotlin
- APP-B 是 Compose-Desktop项目,不得不kotlin
过于絮叨了,我们进入正文。
从架构的理念出发
谨记,实际情况中,MVI、MVVM这些架构均先由Web应用领域提出,用于解决浏览器Web应用研发中的问题。
在后续的应用领域发展过程中,存在共性问题,便引入了这些设计,并结合自身特点进行了拓展。
接下来我们聊一聊理念,不比武功。

图片出自电影一代宗师
MVI的理念
MVI 脱胎于 Model View Intent
- Intent:驱动model发生改变的意图,以UI中的事件最为常见;
- Model:业务模型,包含数据和逻辑,是对应
客观实体的程序建模; - View:表现层的视图,以UI方式呈现Model的状态(以及事件),接受用户输入,转换为UI事件
官方的这幅图很好的呈现了三者之间的驱动关系:
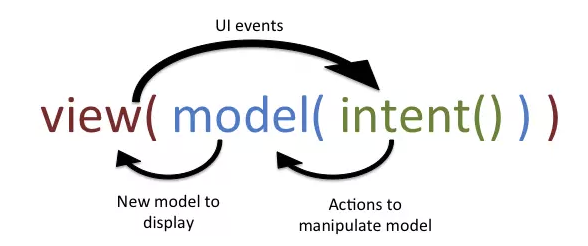
这张图非常简单,它摒弃了驱动方式的细节,只体现了角色与驱动关系。
注意,只要设计中满足 角色和驱动关系 符合上图,就是MVI架构设计,并不限制 驱动方式的实现细节
经典的MVI驱动细节要比上图复杂很多,下文再聊。
从软件设计的原则出发:职责分离并封装 的目的是 解耦 、 可独立变化、复用。
显然,区别于 MVVM 、 MVP 、 MVC,角色上的差别在于 ViewModel、Presenter、Controller、Intent四者,而它们又是View和Model之间的纽带。除此之外,V和M亦稍有不同。
MVC、MVP
MVC、MVP 中,C和P的职责体现为 控制、调度。
MVP中 V 和 M 完全解耦可独立变化,MVC中 M 直接操作 V 耦合高,在web应用中,C 需要直接操作DOM。
MVVM
MVVM中,提倡 数据驱动, 数据源 被剥离到 VM 中,在 双向绑定框架 的加持下,View层的输入反映为数据的变化,数据的变化驱动视图内容。
显然,VM的职责限于维护数据状态,如有必要,驱动View层消费数据状态, 不必再关注如何操作视图。
一般来说,双向绑定框架已经引入观察者模式实现,可响应式驱动,VM一般没有必要关心 响应式驱动和下游观察者生命周期问题
简单思考之后会发现MVVM的问题,它的侧重点在于 利用双向绑定让开发者专注于数据状态的维护,从操作视图更新中得以解放,它难以解决 无天然状态 问题,例如:按钮点击这类事件。
MVI
在MVI中,结合业务背景将UI事件等内容转换为 Intent ,驱动Model层业务,Model层的业务结果反映为 视图状态 + 事件。
因此View层和Model层之间已经解耦,并可以吸收MVVM中的优点采用如下设计:
- 将双向绑定退化为单向绑定,View层消费UI状态流和事件流,这也意味着UI状态的职责精简,它不再承载View层的用户输入等事件
- 将UI状态独立,Model层仅产生
UI状态的局部变化和事件
下图为经典的MVI原理示意图:
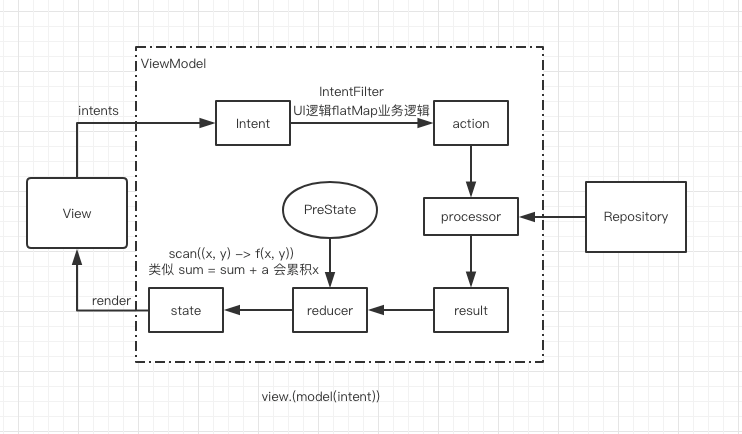
在上文中,我们已经讨论了各个角色的职责,下面逐步展开讨论角色具备的特性和细节知识。
在此之前,还请谨记:合适的才是最好的
没有绝对的最好的设计,只有最合适的设计。
再好的架构,都需要遵循其理念并结合项目因地制宜地进行调整,以获得最佳使用效果。所以请读者诸君务必在阅读时,结合自身项目的情况仔细思考以下问题:
- 引入新框架所解决的痛点、衍生的问题、是否需要进行框架调整?
- 框架中的角色功能,为什么出现,又有怎样的局限?
单向数据流动
MVI拥抱了结构复杂,但能够灵活应对业务编码时的各种情况,按部就班即可。
从MVI原理图中,可以清晰的看到 "数据" 的流动方向。
起始于 Intent,经过分类和选择性消费后产生 Result,对应的reducer函数计算后,得到最新的 State (以及裂变出必要的 Event,图中未体现) ,驱动视图。
注意:
单向是指 单一方向- 此处的
数据是广义的、宽泛的。 - 仅描述数据流的 变化方向 ,与数据流的数量无关,但一般 形成有效工作 均需要两条数据流(上行数据流和下行数据流)
即驱动数据流变化的方向是唯一的,在英文中的术语为:Unidirectional Data Flow 简称 UDF。
MVC、MVP中的痛点
前文我们提到,在MVC和MVP中,着眼于 控制、调度 ,并不强调 数据流 的概念。
View和Model间之间的交互,一般有两种编码风格:双向的API调用、单向的API调用+回调:
注意:以下两图并未体现Controller和Presenter细节,仅表意,从View层出发的API调用和回到View层的UI更新
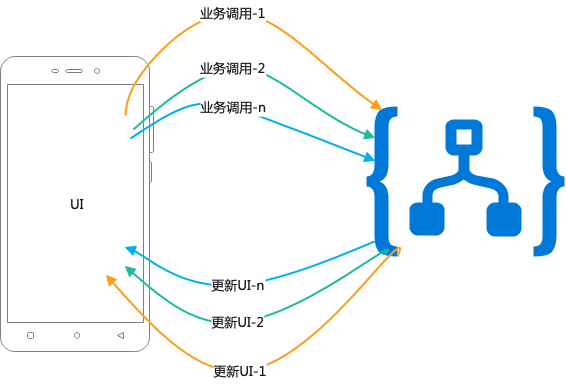
双向API调用如上图。
单向API调用+回调更新UI如上图。
显而易见,这两种方式无法继续抽象,需根据实际业务进行命令式编码。当UI复杂时,难以写出清晰、易读的代码,维护难度激增。
MVVM解决UI更新代码混乱问题
前文我们已经提到:MVVM中通过绑定框架,将UI事件转化为数据变化,驱动业务;业务结果表现为数据变化,驱动UI更新。
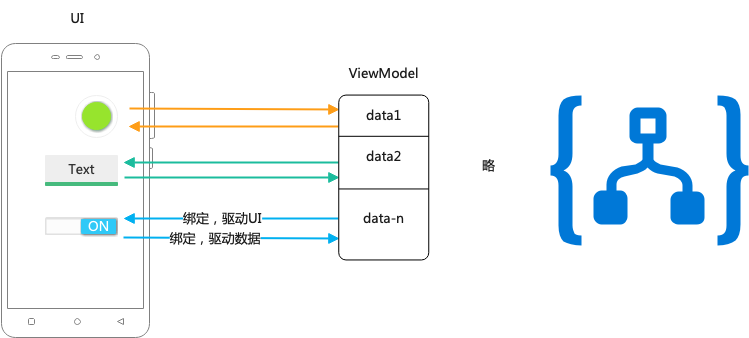
显而易见,维护朴素的数据要比直接维护复杂的UI要简单。
但问题也同时产生,data1的变化有两个可能的原因:
- Model层业务结果使其变化,并期望它驱动UI更新
- View层发生事件,反馈数据变化,并期望它驱动Model层逻辑
因此,框架需要考虑标识数据变化来源、或者其他手段消除方向性所带来的问题。
并且MVVM难以灵活决定的 "何时调用Model层逻辑",即大多数业务中,都需要结合多个属性的变化形成组合条件来驱动Model层逻辑。
本篇并不重点讨论MVVM,故不再展开MVVM解决循环更新的方案,以及衍生的问题。
尽管如此,MVVM中的数据绑定依旧解决了View层更新繁杂的问题。
用Intent灵活决定何时调用Model
既然数据驱动UI有极大的益处,且View层事件驱动ViewModel的数据变化有很多弊端 (需要建立很高的复杂度) ,那自然需要 趋利避害
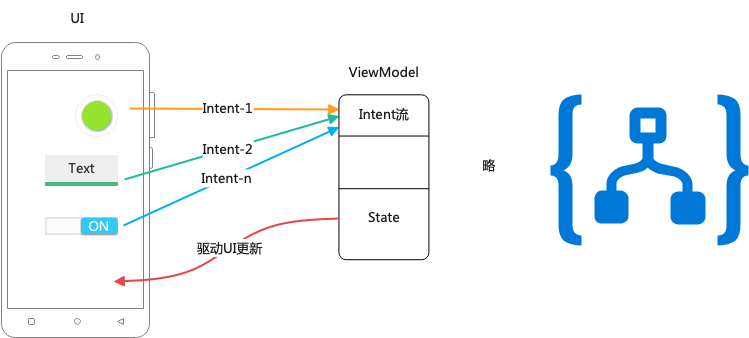
仅保留数据驱动UI的部分,并增加Intent用以驱动Model层业务
在于 MVC/MVP 以及 MVVM 对比后不难得出结论:
- MVC/MVP中,View层通过调用C/P层API的方式最终调用到Model层业务,方式质朴、无难度。但业务量规模增大后接口方法数也会增多,导致C/P层尾大不掉,难以重用。
- MVVM中,VM层总是需要利用
技巧进行模型概念转换,以满足业务响应满足实际需求,需要很深厚的设计经验才能写出非常优秀的代码,这并不友好。
作者按:我个人认为一个友好的设计,不应当剑走偏锋,而应当大巧不工,能够以力破法,达成 "使用者只需要吃透理论就可以解决各类问题" 的目标。
而MVI在架构角色中设计了Intent的角色:
- 它包含了业务调用的意图和数据
- 从设计上可满足
调用与实现的分离 - 架构模型中以Intent流的形式出现,下游对其的
筛选、转换、消费等行为可遵循FP范式(即函数式编程范式、Functional Programming Patterns) ,逻辑的复用粒度为方法级,复用度更高更灵活 - 解决了MVVM中的方向性问题、MVC/MVP 中的灵活度问题等
单一可信数据源
我猜测读者诸君都曾听过这个词,将 单一可信数据源 拆解一下:
- 单一
- 可信
- 数据源
在MVI背景下,数据源 指的是视图对应的数据实体,它代表视图的内容状态。
可信指从数据源中获取的数据是 最新的、完整的、可靠的,否则是不可信的,我们没有理由在编码中使用不可信的数据源。
单一是指这样的数据源仅一个。
在经典设计中,其内涵如下图:
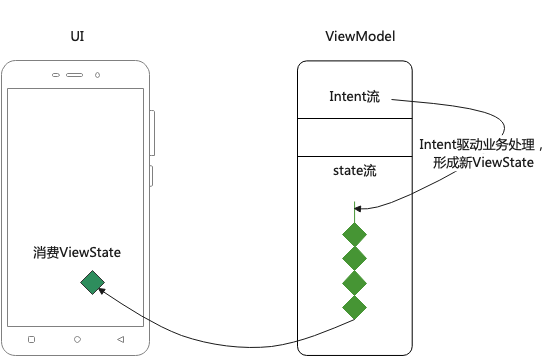
- 按照视图的 所有的 内容状态,定义一个不可变的
ViewState - 按照业务初始化 ViewState 实例
- Model业务生成驱动 ViewState变化的Result
- 计算出新状态,Reduce(Pre-ViewState,Result) -> New-ViewState
- 更新数据源
- View层消费ViewState
借助于数据绑定框架,可以很方便地解决视图更新的问题。
想象一下,此时页面UI非常复杂……

如果僵化的信奉这样的 单一 ,情况会如何呢?
- 复杂(大量属性)的ViewState
- 复杂的UI更新计算,e.g. 100个属性变了2个,依然需要计算98个属性未变或者全量强制更新
在 APP-A和APP-B中,我分别使用了 DataBinding和Compose,但均无法避免该问题。
何为单一
从机器执行程序的原理上看,我们无法实现 多个内容一致的数据源 在 任意时刻 满足 最新的、可靠的。
将视图视为一个整体,规定它只拥有 一个 可信的数据源。在此基础上看局部的视图,它们也顺其自然地仅拥有一个可信的数据源。
反过来看,当任意的局部视图仅具有一个可信数据源时,整体视图也仅有一个逻辑上的可信数据源。
据此,我们可以对 经典MVI实现 进行一定程度的改造,将ViewState进行局部分解,使得UI绑定部分的业务逻辑更 清晰、干净。
请注意,复杂度不会凭空消失,我们为了让 "UI绑定的业务逻辑更清晰、干净"、"更新UI的计算量更少",将复杂度转移到了ViewState的拆分。拆分后,将具有 多个视图部件的单一可信数据源,注意,为了不引起额外的麻烦、并且便于维护扩展,建议遵守以下条件:
- 基于业务需求,组合数据源形成新数据源
- 不在数据源的逻辑范围之外进行数据源组合操作
举个虚拟的例子:用户需要实名认证 且 关注博主 ,才在界面上显示某功能按钮。下面使用代码分别演示。
考虑到RxJava的广泛度依旧高于Kotlin-Coroutine+flow,数据流的实现采用RxJava
注意,考虑到读者可能会编写demo做UDF局部的验证,下文中的代码以示例目的为主,兼顾编写场景冒烟的方便性,流的类型不一定是构建完整UDF的最佳选择。
经典实现
在经典MVI实现中,需要先定义ViewState
data class ViewState(
/*unique id of current login user*/
val userId: Int,
/*true if the current login user has complete real-name verified*/
val realNameVerified: Boolean,
/*true if the current login user has followed the author*/
val hasFollowAuthor: Boolean
) {
}
并定义ViewModel,创建ViewState流,忽略掉其初始化和其他部分
class VM {
val viewState = BehaviorSubject.create<ViewState>()
//ignore
}
并定义View层,忽略掉其他部分,简单起见暂时不使用数据绑定框架
class View {
private val vm = VM()
lateinit var imgRealNameVerified: ImageView
lateinit var cbHasFollowAuthor: CheckBox
lateinit var someButton: Button
fun onCreate() {
//ignore view initialize
vm.viewState.subscribe {
render(it)
}
}
private fun render(state: ViewState) {
imgRealNameVerified.isVisible = state.realNameVerified
cbHasFollowAuthor.isChecked = state.hasFollowAuthor
someButton.isVisible = state.realNameVerified && state.hasFollowAuthor
//ignore other
}
}
在JS中,JSON并不能附加逻辑,基本等价于Java中的POJO,故在数据源外部处理简单逻辑的情况较为常见。而在Java、Kotlin中可以进行适当的优化,适当封装,使得代码更加干净便于维护:
data class ViewState(
//ignore
) {
fun isSomeFuncEnabled():Boolean = realNameVerified && hasFollowAuthor
}
class View {
//ignore
private fun render(state: ViewState) {
//...
someButton.isVisible = state.isSomeFuncEnabled()
}
}
拆分实现
依旧先定义逻辑上完整的ViewState:
class ComposedViewState(
/*unique id of current login user*/
val userId: Int,
) {
/**
* real-name-verified observable subject,feed true if the current login user has complete real-name verified
* */
val realNameVerified = BehaviorSubject.create<Boolean>()
/**
* follow-author observable subject, feed true if the current login user has followed the author
* */
val hasFollowAuthor = BehaviorSubject.create<Boolean>()
val someFuncEnabled = BehaviorSubject.combineLatest(realNameVerified, hasFollowAuthor) { a, b -> a && b }
}
定义ViewModel,子模块数据流均已定义,故而无需再定义全ViewState的流
class VM(val userId: Int) {
val viewState = ComposedViewState(userId)
//ignore
}
编写View层的UI绑定,同样简单起见,不使用数据绑定框架
class View {
private val vm = VM(1)
lateinit var imgRealNameVerified: ImageView
lateinit var cbHasFollowAuthor: CheckBox
lateinit var someButton: Button
fun onCreate() {
//ignore view initialize
bindViewStateWithUI()
}
private fun bindViewStateWithUI() {
vm.viewState.realNameVerified.subscribe {
renderSection1(it)
}
vm.viewState.hasFollowAuthor.subscribe {
renderSection2(it)
}
vm.viewState.someFuncEnabled.subscribe {
renderSection3(it)
}
//...
}
private fun renderSection1(foo:Boolean) {
imgRealNameVerified.isVisible = foo
}
private fun renderSection2(foo:Boolean) {
cbHasFollowAuthor.isChecked = foo
}
private fun renderSection3(foo:Boolean) {
someButton.isVisible = foo
}
}
例子较为简单,在实际项目中,如果遇到复杂页面,则可以分块进行处理。
注意:实际情况中,并没有必要将每一个子数据源拆分到一个View级别的控件,那样过于啰嗦,例子因非常简单而无法丰满起来。 e.g. 针对每一块视图区,例如作者区域,定义子ViewState类,创建其数据流即可。
作者按:务必评估,在一次Model业务产生的Result中,会引起数据流下游的更新次数。 为避免产生不可预期的问题,可通过类似以下方式,使下游响应次数表现和经典实现的情况一致。
额外定义PartialChange流或者功能等价的流,它用于标识 reduce 计算的开始和结束,可以将此期间的数据流的变化延迟到最后发送终态
更加推荐定义功能上等价的流
class ComposedViewState(
/*unique id of current login user*/
val userId: Int,
) {
internal val changes = BehaviorSubject.create<PartialChange>()
//ignore
val someFuncEnabled =
BehaviorSubject.combineLatest(realNameVerified, hasFollowAuthor) { a, b -> a && b }.sync(PartialChange.Tag, changes)
}
inline fun <reified T, S> Observable<T>.sync(tag: S, sync: BehaviorSubject<S>): Observable<T> {
return BehaviorSubject.combineLatest(this, sync) { source, syncItem ->
if (syncItem == tag) {
syncItem
} else {
source
}
}.filter { it is T }.cast(T::class.java)
}
修改PartialChange,为reduce函数添加边界:
PartialChange是Model产生的Result的表现物,封装了ViewState的reduce函数逻辑,即如何从 Pre-ViewState 生成 新 ViewState
sealed class PartialChange {
open fun reduce(state: ComposedViewState) {
}
/**
* 同步标记,从头开始到真实PartialChange之间,流的状态生效
* */
object Tag : PartialChange()
object None : PartialChange()
class Foo(val a: Boolean, val b: Boolean) : PartialChange() {
override fun reduce(state: ComposedViewState) {
state.changes.onNext(Tag)
state.realNameVerified.onNext(a)
state.hasFollowAuthor.onNext(b)
state.changes.onNext(this)
}
}
}
要想优雅,需要工具
采用响应式流,避免命令式编码
想来这一点已不需要多做解释。
在Android中,存在 LiveData 组件,它通过简单的方式封装了可观测的数据,但实现方式简单也限制了它的功能 不够强大 。因此,建议使用 RxJava 或者 Kotlin-Coroutine & flow 构建数据流。
本节便不再展开。
采用数据绑定框架
采用 jetpack-compose 或者 DataBinding 均可以移除枯燥的UI命令式逻辑,在APP-A中我使用了DataBinding,在APP-B中我使用了Compose。
在 ViewState的代码很棒时,均可以获得优秀的编程体验,从啰嗦的UI中解放出来。
作者的个人观点:
关于Compose。Compose依旧属于较新的事物,在商业项目中使用存在学习门槛和造轮工作。在目标用户具有较高容忍度的情况下,已然可以进行尝试。
关于DataBinding。一个近乎毁誉参半的工具,关于它的批判,大多集中于:xml中实现的逻辑难以阅读、维护,这实际上是对DataBinding设计的误解而带来的错误使用。
DataBinding本身具有生成VM层的功能,但这一功能并不足够强大,且没有完善的使用指导,而在官方Demo中过度宣传了它,导致大家认为DataBinding就该这样使用。
仅使用基础的数据绑定功能、和Resource或者Context有关的功能(例如字符串模板)、组件生命周期绑定等,适度自定义绑定。
何为状态、何为事件。最后的一公里
首先区别于上文提到的UI事件,这里的状态和事件均产生于数据流的末段,而UI事件处于数据流的首段。
UI事件属于:A possible action that the user can perform that is monitored by an application or the operating system (event listener). When an event occurs an event handler is called which performs a specific task
在展开之前,先用一张图回顾总结上文中对于 单向数据流 & 单一可信数据源 的知识
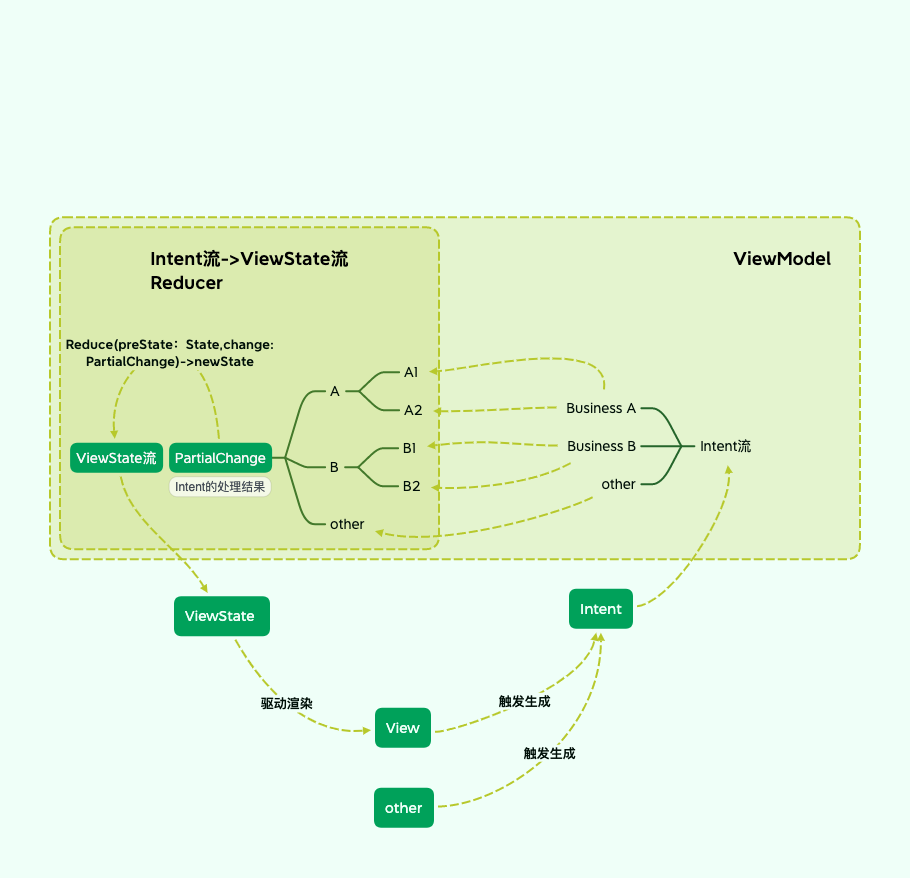
在 单向数据流动 章节中,提到了MVI的UDF设计:
- 系统捕获的UI事件、其他侦听事件(例如熄屏、应用生命周期事件),生成Intent,压入Intent流中
- ViewModel层中筛选、转换、处理Intent,实际是使用Model层业务,产生业务结果,即PartialChange
- PartialChange经过Reducer计算处理得到最新的ViewState,压入ViewState流
- View层(广义的表现层)响应并呈现最新的ViewState
在 单一可信数据源 章节中,提到View层应当采用 单一可信数据源
在这张图中,我们仅体现了 状态 即 ViewState。
关于GUI程序的认知
在展开前,先聊点理念上的内容。请读者诸君思考下自己对于GUI程序的认知。
作者的理解:
程序狭义上是计算机能识别和执行的一组指令集,编程工作是在程序世界对
客观实体、业务逻辑进行 建模和逻辑表达。而GUI程序拥有
用户图形界面, 除了结合硬件接收用户交互输入外,可以将程序世界中的模型以用户图形界面等方式表现给用户。表现出来的内容代表着客观实体
其本质目的在于:通过 描述特征属性 、 描述变化过程 等方式让用户感知并理解
客观实体
而除了通过 程序语言描述 、 程序世界模拟展现 外,同样可以通过 自然语言描述 达到目的,这也是产品经理的工作。
当然,产品经理往往需要借助一些工具来提升自己的自然语言表达能力,但无奈的是能用数学公式和逻辑推演表达需求的产品经理太少见了。
写这段只是为了引入 他山之石 。
First-Order logic
在数学、哲学、语言学、计算机科学中,有一个概念 First-Order logic,无论是产品需求还是计算机程序,都可以建立FOL表达。
当然,本篇不讨论FOL,那是一个很庞大且偏离主题的事情。我仅仅是想借用其中的概念。
FOL表达 Event或者State时:
- Event 体现的是特定的变化
- State 体现的是客观实体在任意时刻都适用的一组情况,即一段时间内无变化的条件或者特征
不难理解,变化是瞬时的,连续的变化是可分的。
但在人机交互中,瞬时意义很小,我们的目的在于让用户感知。
例如:"好友向你发送了一条消息的场景中",消息抵达就是Event,它背后潜藏着 "消息数的变化"、"最新消息内容的变化" 等。 在常见的设计中:
- 应用需要弹出一个气泡通知用户这一事件
- 应用需要更新消息数,消息列表内容等,以呈现出最新的State
而为了让用户感知到,气泡呈现时长并不是瞬时的,但在产品交互设计中依旧将其定义为事件。
分离状态和事件,不是吃饱撑得
看山是山、看水是水
此时此刻,答案已经很明显。
在通用的产品设计中,状态和事件有不同的意义,如果程序中不分离出两者,则必然是自找麻烦,这是公然挑衅 面向对象编程 的行为。如果不明确定义不同的Class,则势必导致代码混乱不堪,毕竟这是违背编程原则的事情。
在大多MVVM设计中,状态和事件未分家,导致bug丛生,这一点便不再展开。
如何区分Event和State
State是一段时间内无变化的条件或者特征,它天然的 契合 了位于表现层的主体内容所对应的 数据模型特征。
Event是特定的变化,它在表现层体现,但与State的生命周期不一致,且并无一一对应的关系。
基于经验主义,我们可以机械地、笼统地认为:页面主体静态内容所需要的数据属于State范畴,气泡提醒等短暂的物体所需要的数据属于Event范畴。
从逻辑推演的角度出发,进行 等价逻辑推断 和 条件限定下的逻辑推断 ,一定序列的Event可以模型转换为State。
事件粘性导致重复?只是框架设计的bug
看山不是山,看水不是水
前面提到,State是一段时间内无变化的条件或者特征,所以在程序设计中State具有粘性的特征。
如果Event也设计出这样的粘性特征并造成重复消费,明显是违背需求的,无疑是框架设计的Bug。此问题在各大论坛中很常见。
注意,我们无法脱离实际需求去二元化的讨论事件本身该不该有粘性特征,只能结合实际讨论框架功能是否存在bug
如果要实现以力破法,在框架设计层面上 Event体系的设计要比State体系要复杂 。因为从交互设计上:
- State 只需要考虑呈现的准确性和及时性,除去美观、可理解性等等
- Event 需要考虑准确性、优先级、及时性、按条件丢弃等等,除去美观、可理解性等等
举个例子:网络连接问题导致的Web-API调用失败需要使用Toast提示网络连接失败
不难想象:
- 可能一瞬间的断开网络连接,会导致多个连接均返回失败
- 可能连接问题未修复,10秒前请求失败,当前请求又失败了
难道连续弹出吗?难道和上一次Event一致就不消费吗?...
或许您会使用一些 剑走偏锋的技巧 来解决问题,但技巧总是建立在特定条件下生效的,一旦条件发生变化,就会带来烦恼,您很难控制上游的PM和交互设计师。
所以在框架层面需要针对产品、交互设计的泛化理念,设计准确的、灵活的Event体系。
准确的、灵活的Event体系
看山还是山,看水还是水
回到FOL中,为了更加准确的表达Event和State的含义,还需要一些额外的参数,例如:参与者、地点、时间 等。
想通这一点会发现,产品中定义的Event事件、及其消费逻辑均含有隐藏属性,例如:
- 发生时间
- 客观有效期
- 判断有效的条件(如呈现的条件)
- 判断失效的条件 ,用于实现提前失效
产品经理和交互设计师一般会使用 "响应时间"、"优先级" 等词描述它们,但一般不严谨、不成体系,带来期望不一致的问题
反观State流,它代表了界面主体内容在时间轴上的完整变化,任意一个时间点均可以得出界面内容所对应的条件和特征。一旦State流中出现一个新的状态,它均被及时的、准确的在表现层予以体现。
不难理解,一个State的生命周期为 从init或者reducer计算生成开始 至 reducer计算出新State、宿主生命期结束为止,在State流中已然暗含:
- State之间无生命周期重叠
- 所有State的生命周期相加可填满时间轴
前文提到Event是瞬时的,所以Event本身并没有实质意义上的生命周期,为了方便表述,我们将 "Event从生成到在表现层不可观测的阶段" 定义为Event生命周期
而Event流 不同于 State流 ,因为Event的生命周期情况更加复杂:
- Event可能存在生命周期重叠
- 所有Event的生命周期相加可能无法覆盖完整的时间轴
需要额外设计实现 。实现这一点后,从Event流中分流(以及裂变+组合)出的 子流 将和State流 性质一致。
此刻,您会发现,根据不同类型的事件交互控件所对应的交互特征,又将Event流结合条件流衍生出各个State流。完整的数据流细节如下:
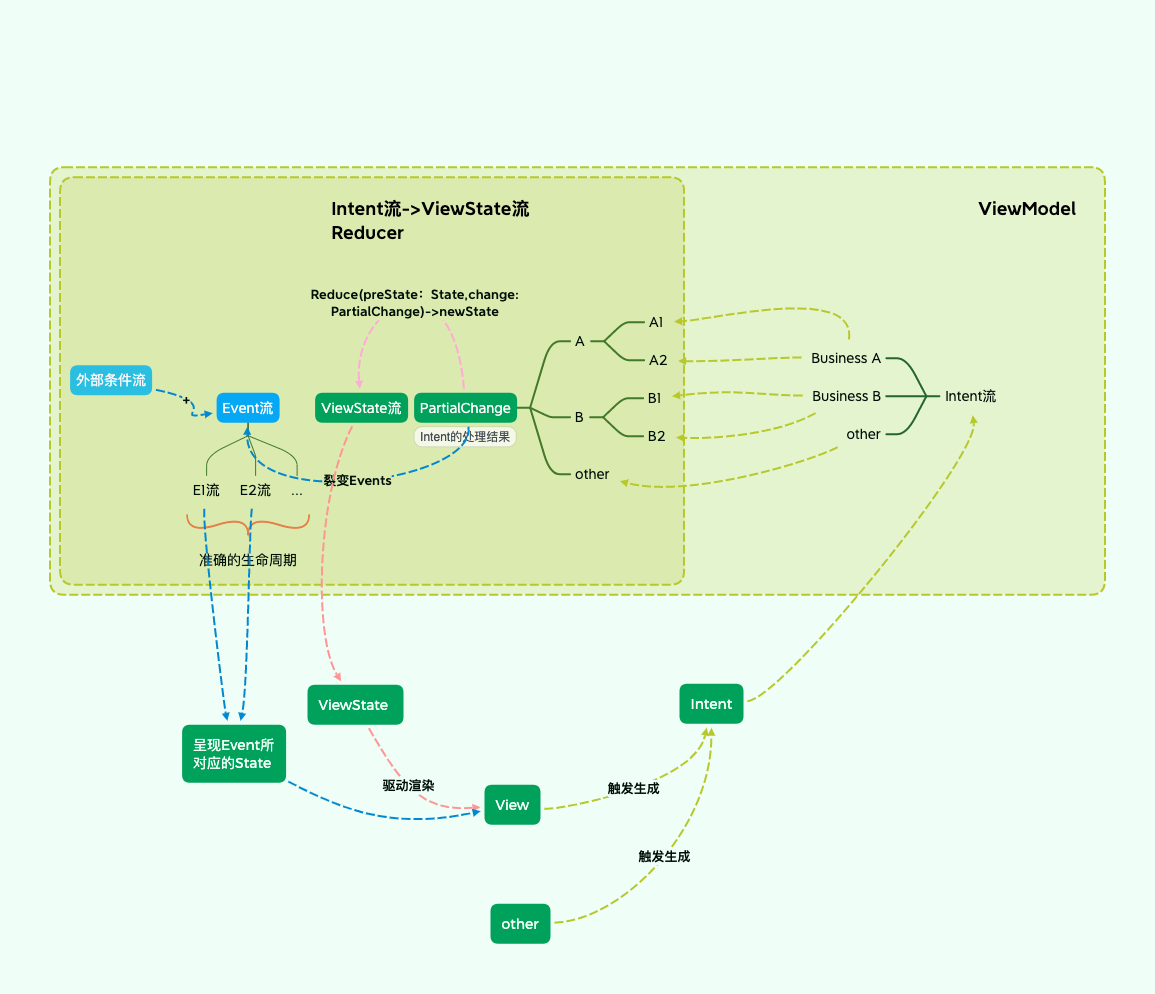
作者按:在图中省略了Event分流转变为子State流的过程,因为它需要遵循特定产品交互机制
结语
这篇文章,从5月计划写,到6月动笔,断断续续,草稿写了很长,几经删改依旧留有很长的篇幅,虽已竭力尽智,但任觉文字上有表意未通透之处,欢迎在评论区讨论。