Java多线程基础--线程的创建与线程池管理
前言
各位亲爱的读者朋友,我正在创作 Java多线程系列 文章,如果您觉得内容还不错,还请点赞支持一下。
在上一篇文章 中,我们回顾了线程生命周期、线程之间相互协作的知识,本篇我们继续挖掘,增强对线程的理解。
作者按:本篇按照自己有限的知识进行整理,如有谬误,还请读者在评论区不吝指出
了解系列以及总纲:Java多线程系列
重要声明:
出于 方便叙述 或 帮助基础尚且薄弱的读者理解文章内容 的目的,文中举了一些例子,但这些例子并 不能 百分百准确的对应Java中的概念,甚至有些幼稚。
读者朋友们应当注意到这一点,并且清晰的意识到自己的目标是理解Java中的概念与设计,而不必纠结于例子是否有失偏颇。
本篇博客的内容较为散碎,以下是内容大纲,您可以结合它挑选感兴趣的内容片段阅读、重新梳理知识
线程的创建与启动
在上一篇文章中,我们提到,调用 Thread#start() 即可启动该线程,而并未挖掘虚拟机 真正启动 一个线程的 具体过程。
可能会让您失望,这一篇依旧不会挖掘这一细节,因为它对设计、编写优质的多线程应用毫无帮助。
如果您对此感兴趣,以下文章可能会有帮助:
- 面试官问如何启动Java 线程 未查询到源头作者信息
- 从Java到C++,以JVM的角度看Java线程的创建与运行 作者Van96
先回归到概念:
操作系统中的Thread:是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位
JVM中的Thread:A thread is a thread of execution in a program. The Java Virtual Machine allows an application to have multiple threads of execution running concurrently. -- 似乎解释了,又似乎没有
"编写应用程序时,不会为了展现自己已经掌握了启动线程的知识而去启动线程",即线程是手段,这一点并不难理解。应用程序使用线程的目的在于 完成既定任务 , 并且基于多线程并发能力提高程序的运行效率、或者基于线程的特性界定职责边界使程序有序运行。
举个例子,工厂接了一批订单,需要在能力一致的一批工人中选择一批完成订单的生产,不难理解:工厂老板在意的是订单的完成,而不是工人的名字、星座、爱好。
那么如何定义线程需要完成的任务呢?
在最初的JDK中,存在两种方式:
- 继承Thread类、覆写
run()方法定义任务
class PrimeThread extends Thread {
long minPrime;
PrimeThread(long minPrime) {
this.minPrime = minPrime;
}
public void run() {
// compute primes larger than minPrime
}
}
- 组合优于继承的典型例子:实现Runnable接口,作为Thread的任务
class Foo {
class PrimeRun implements Runnable {
long minPrime;
PrimeRun(long minPrime) {
this.minPrime = minPrime;
}
public void run() {
// compute primes larger than minPrime
}
}
foo() {
PrimeRun p = new PrimeRun(143);
new Thread(p).start();
}
}
随着JDK的发展,也有更多的方式定义任务,我们将在后续的系列文章中展开。
至此,您应该已经意会了 JDK doc 中所说的 a Thread is a thread of execution in a program
线程池
回到前文举得例子,工厂经过长时间的运转,积累了足够的经验,老板突然顿悟:只要工人能够胜任工作,自己完全没有必要了解工人,只需要:
- 评估生产任务量
- 制定好生产计划
- 把任务和计划交给产线即可
完全不用在意是张三做还是李四做。
工人形如线程,产线便形如线程池。结合工厂的实际情况与任务的特性,可以凝练出 几种产线管理方式 。
在Java中,直接或者间接的依靠配置 ThreadPoolExecutor 获得线程池。
作者按:通过简单的搜索,可以发现大量的探讨线程池的博客,可能受面经影响,部分博客均围绕几个常见地面试问题展开。 但务必注意,线程池的知识内容远不止面试题题干所表现的那些内容!相比之下,理解线程池的设计更为重要。
而我的文字功力有限,无法像教科书那样,顺着严谨的大纲递进式展开,还让文字显得 深刻且有趣,只能尽可能推测读者的兴趣点,展开以下内容
接下来,让我们结合生活经验,以工厂产线为例子,反思推导线程池的设计,了解 ThreadPoolExecutor 最基本的知识。
ThreadPoolExecutor 核心设计
上文中,我们以 产线 类比 线程池 ,"工厂对工人的管理方式" 来类比 "线程池的管理设计" ,并且您一定注意到两处重点:任务 、 工人
在线程池中, 上岗工作的线程 可以类比为 工人 ,完成产线收到的任务。
注意,该类比并不完全准确
不难推测,线程池存在两个核心内容:
- 任务队列
BlockingQueue<Runnable> workQueue - 工作者集合
HashSet<Worker> workers
任务队列用于存储任务,您应该已经注意到,它使用的是juc下的 BlockingQueue 接口。它的本质还是队列,附加了两种特殊的操作:
- 取 时满足 (或等待至满足) 队列非空
- 存 时满足 (或等待至满足) 队列有空余空间
既然是接口,自然可以有不同的实现,您可以使用不同的实现作为线程池的任务队列。
在线程池设计中,通过依赖抽象 即BlockingQueue 进行了解耦,只关心存取的时机。您可以自行决定队列的特性,诸如大小、存储方式、优先级排序等
在先前的系列文章中还未涉及 BlockingQueue ,计划将于后续系列文章中展开,故本文也不会围绕它展开内容
接下来,让我们看一看 一个人上岗成为产线工人的全过程 ,即 Thread 成为线程池 Worker 的过程
成为线程池中的工作者
产线确定了一个岗位,管理者把岗位信息给到人力资源部门,并申请配给人力:getThreadFactory().newThread(this)
人力资源部门派遣了一个 Thread 小T 给到产线,小T已经接受了技能培训,并且知道上岗后从产线的 任务队列 中取任务、出卖体力完成它即可, void runWorker(Worker w)。
小T 就成为了一个 Worker。
您可能意识到,线程池只关心线程的管理,并不关心线程的创建细节,所以再次依赖抽象,对线程创建细节进行了解耦:
public interface ThreadFactory {
Thread newThread(Runnable r);
}
关于Worker的定义、职责,泛读以下源码即可了然于心:
public class ThreadPoolExecutor extends AbstractExecutorService {
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker. */
public void run() {
runWorker(this);
}
//其他略
}
public ThreadFactory getThreadFactory() {
return threadFactory;
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
//锁处理和判断略
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
}
//异常略
finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
}
您可能留意到,近年来的一些社会不良事件中总会出现一个词:临时工。当然,我并没有任何在此讨论社会问题的意愿, 一条生产线有固定的岗位,也会有按需产生的临时工岗位,甚至完全是临时工岗位,这并不难理解。而线程池也有这样的设计。
public class ThreadPoolExecutor extends AbstractExecutorService {
/**
* Core pool size is the minimum number of workers to keep alive
* (and not allow to time out etc) unless allowCoreThreadTimeOut
* is set, in which case the minimum is zero.
*/
private volatile int corePoolSize;
/**
* Maximum pool size. Note that the actual maximum is internally
* bounded by CAPACITY.
*/
private volatile int maximumPoolSize;
}
注意,线程池在管理时,对线程是一视同仁的,只关心核心线程数量、最大线程数量,并不会依据线程的特征将其分化为 核心/非核心。
产线如何确定一个岗位
上一节我们提到,产线确定了一个岗位后,向人力资源部门要人并安排成为产线工人。
那么产线是如何确定一个岗位的呢?即 线程池如何确定需要增加一个Worker?
产线不会无缘无故的安排工人上岗工作,必然是收到了生产任务,否则就成了合理摸鱼。
顺理成章的,线程池收到一个任务时,在相应的Size限制没有达到时,优先考虑安排线程进行处理,而不是丢到任务队列中等待。
在先前的系列文章中,我们已经了解到,启动线程是较为昂贵了,虽然线程池规划了 核心线程的数量 和 最大线程数量 ,但也不会一开始就全员上岗,而是在任务抵达时逐步的安排线程上岗。
尝试 安排线程上岗 时,
- 需先判断线程池工作状态,如果线程池已经关闭,自然不会再增加线程,返回失败。比如产线准备停产了,已经接的任务会安排处理,但肯定不会再招工。
- 如果线程池正常工作,则检查线程数量是否可以继续增加
- 如果可以继续增加,则尝试更新线程总数,如果失败,则说明在其他线程中也触发了addWorker逻辑,那么线程池的工作状态也可能发生了改变,如果没有改变,则重复步骤2,否则回到步骤1继续检测
- 上一节中的内容,得到Thread实例并让其成为Worker,开始干活
整个过程中有CAS操作,鉴于有系列文章的撰写计划,文中不再展开,相应代码可参考gist:
向产线(线程池)下达任务
联想一下,市场部门小王拿到了一笔单子,来到产线找到负责人老张,让老张安排干掉
- 老张拿起了职工工作排期表,发现 还有固定岗位空着 ,则直接向人力资源要人上岗干活;
- 注意,招人上岗 可能失败 ,比如老张手上的信息不及时,现在已经满额了,也有可能厂长决定产线要停掉,通知人力资源不要再派人了
- 假如固定岗位招不来人,老张继续核实: 产线未停产 且 可纳入计划,在未停产且可纳入计划的情况下,把任务排进了计划
- 老张还是很严谨的,又再次核实产线生产状态,如果产线已经停产并且该任务没有被领取,则把任务拒掉
- 否则检查工人是否在岗,如没有工人在岗,则向人力资源部门要一个 临时工 处理 任务队列中的任务, 如果要不来人,任务也放着
- 如果产线停产了或者排不进计划了,老张精通人情世故,表示看看能不能拉个临时工来,能拿到人就直接处理,否则就只能拒绝了,
- 如果是产线停了或者达到了最大人数,则要不来人 -- 参考上个小节
- 否则临时工会处理该任务
而线程池中与此过程也非常类似,代码比较简短:
public class ThreadPoolExecutor extends AbstractExecutorService {
public void execute(Runnable command) {
if (command == null) // 小王在忽悠人
throw new NullPointerException();
int c = ctl.get();
//1.
if (workerCountOf(c) < corePoolSize) {
//1.i
if (addWorker(command, true))
return;
c = ctl.get();
}
//2.
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (!isRunning(recheck) && remove(command)) // 2.i
reject(command);
else if (workerCountOf(recheck) == 0) // 2.ii
addWorker(null, false);
} else if (!addWorker(command, false)) // 3
reject(command); // 3.i
}
}
当你拒绝任务
虽然打工人和老板都想任务及时可靠的被完成,但总有不如意的时候,某些情况下,线程池将不得不拒绝任务。
上文中已经提到:线程池已经关闭、任务队列已经排满。
当线程池拒绝任务时,事情总得有个说法,JDK设计了接口:
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
在线程池实例化时,需要指明拒绝策略。
JDK中提供了4个策略:
- CallerRunsPolicy -- 在线程池未关闭情况下,访问者线程直接负责处理
- AbortPolicy -- 抛出
RejectedExecutionException异常,这是运行时异常, 默认策略 - DiscardPolicy -- 这个任务就此罢休
- DiscardOldestPolicy -- 只要线程池没关闭,这件事情就非得干,把排在最前的任务踢掉,重走任务下达流程
蓦然回首,回看构造函数
ThreadPoolExecutor 提供了一系列重载构造函数用于获取特定实例

public class ThreadPoolExecutor extends AbstractExecutorService {
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler
) {
//ignore 参见gist https://gitee.com/leobert_253/codes/wh495q63tvlipum2snca131
}
}
以此为例
- int corePoolSize, 核心线程数量
- int maximumPoolSize, 最大线程数量
- long keepAliveTime, 配合 unit 表示的时间,作为IDLE 线程等待任务的超时时间,核心线程如果不允许采用超时机制将一直等待任务(默认)
- TimeUnit unit, 配合 keepAliveTime
- BlockingQueue
workQueue 任务队列 - ThreadFactory threadFactory 线程创建工厂
- RejectedExecutionHandler handler 拒绝任务时的策略
当然,这些参数存在一些限制和校验,可参考 gist 进一步阅读,摘自JDK1.8。
线程池的状态标识-ctl的设计
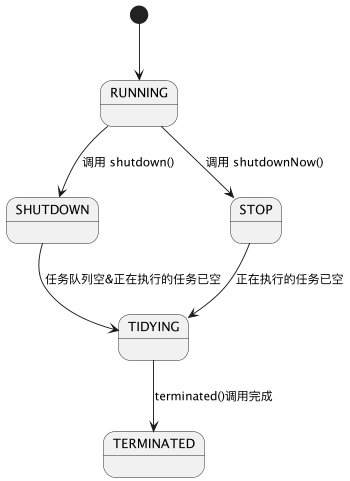
前面的内容中已经提到了线程池Shutdown的状态,线程池具有5个状态,先看一眼代码: 相应的二进制补码已标识
注意,计算机中以补码表示数,如果是有符号数,最高位表示符号,1为负、0为非负,非负数其原码和补码一致,负数的补码: 取原码,符号位不变(保持1),其他位取反,然后加1 得到补码
public class ThreadPoolExecutor extends AbstractExecutorService {
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
/**
* 即29
* */
private static final int COUNT_BITS = Integer.SIZE - 3;
/**
* 0010 0000 00000000 00000000 00000000 -1 =>
* 0001 1111 11111111 11111111 11111111
*
* wc = ctl & CAPACITY 低29位存储wc
* state = ctl & ~CAPACITY 高三位存储状态
* */
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
//补码 111 29个0
private static final int RUNNING = -1 << COUNT_BITS;
//补码 000 29个0
private static final int SHUTDOWN = 0 << COUNT_BITS;
//补码 001 29个0
private static final int STOP = 1 << COUNT_BITS;
//补码 010 29个0
private static final int TIDYING = 2 << COUNT_BITS;
//补码 011 29个0
private static final int TERMINATED = 3 << COUNT_BITS;
private static int ctlOf(int rs, int wc) {
return rs | wc;
}
}
很显然,ThreadPoolExecutor 将32位的int分为不同的区域标识信息,在多线程背景下,使用AtomicInteger,但本质还是int。
将 32位中的 高三位用于存储状态信息,低29位存储 worker-count(即wc),信息存储于ctl中,非常传统的位运算设计。
考虑到篇幅和阅读体验,其他相关的位运算API已经剥离到 gist , 通过位运算解出状态、wc,判断状态大小等
- Running 运行状态(实例化后的默认状态)
- Shutdown 不接收新任务,处理任务队列中的任务
- Stop 不接收新任务,不处理任务队列中的任务,并且中断正在处理的任务
- Tidying 所有的任务已终止时的一个暂态,随后将执行terminate(),成功后进入Terminated状态
- Terminated 彻底终止
生命周期变化如下:
线程池目的
此时,请您想一想,创建线程池机制的目的是什么?
前文提到,线程池是对线程进行管理,显然还不是根源。
- 降低资源消耗。 重复利用已创建的线程,可降低线程创建和销毁造成的消耗。
- 提高响应速度。 线程池中有线程值守,当任务到达时,不需要每次都等待线程创建。注意,并不排除任务排队、必要的线程启动情况
- 提高线程的可管理性,对系统运行状态进行调优。 线程是稀缺资源,不能无限制的创建,使用线程池可以进行统一的分配、监控、调优。
面经常客,JDK中提供的线程池
您一定阅读过一些面经,其中包含线程池的题目。作者可能在引导您向着 "JDK中特定的API所提供的线程池特征" 方面展开作答,或者题目看起来就是这样,也许就是一个面试陷阱
作者按,不要单纯的为了应付面试和放弃了学习的初心。结合问题 讲清楚线程池的设计 要比 单纯的、枯燥的罗列通过调用Executors中的API得到的线程池对应的特征 有意义
在JDK1.5中,Java凝练了4种配置方式,可获得特定管理方式的线程池:
Java依据其特征作为Executors中的方法命名,借用它们作为这4类线程池的别名
- FixedThreadPool 数量固定、线程可重用
- SingleThreadExecutor 仅单个线程
- CachedThreadPool 会根据需要创建新线程的线程池
- ScheduledThreadPool 可定期或周期执行任务的线程池
前文已经提到,它们直接或者间接的使用了 ThreadPoolExecutor,而不是4个继承类!按照其API命名给了它们别名,但并不是类名!
FixedThreadPool
JDK中提供的包装方法如下:
public class Executors {
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
}
很显然,FixedThreadPool 是一个定额的池,nThreads 即为核心线程数量,亦为最大线程数量,注意值必须大于0。
这条产线的工人就很惨,活多了也不会加派人手,任务排队等待线程空闲;不来活也要在岗位上待着,不会释放线程。
以 LinkedBlockingQueue 作为任务队列,先到的任务先被处理,并且它是无界的。
SingleThreadExecutor
顾名思义,我们会得到一个单一线程的线程池。
public class Executors {
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
}
可能您会疑惑,
new ThreadPoolExecutor(
1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory
)
已经得到了一个 核心线程数、最大线程数均为1的线程池,为啥要增加 FinalizableDelegatedExecutorService 的参与?
前文未提及但您可能知道,ThreadPoolExecutor是可以重新配置的!例如重新设置核心线程数量:
public class ThreadPoolExecutor {
public void setCorePoolSize(int corePoolSize) {
if (corePoolSize < 0)
throw new IllegalArgumentException();
int delta = corePoolSize - this.corePoolSize;
this.corePoolSize = corePoolSize;
if (workerCountOf(ctl.get()) > corePoolSize)
interruptIdleWorkers();
else if (delta > 0) {
int k = Math.min(delta, workQueue.size());
while (k-- > 0 && addWorker(null, true)) {
if (workQueue.isEmpty())
break;
}
}
}
}
而 FinalizableDelegatedExecutorService 继承自 DelegatedExecutorService,扩展了在 finalize() 时关闭线程池。
而后者是一个Wrapper,仅暴露 ExecutorService 接口的功能,通过委托的方式封闭了重新配置线程池的能力。
CachedThreadPool
该池将使用 "线程对象" 缓存方案,核心线程数量为0,全部为临时工,并且基于上文的知识:
- 如果池中没有Worker,则会新增Worker处理,否则任务放入任务队列等待。
- 非核心线程可以运用获取任务超时时间,当获取任务超时时,则
processWorkerExit下岗
public class Executors {
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
}
ScheduledThreadPool
public class Executors {
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
}
不同于前三者,此时得到的线程池可 定时 处理任务。
为了实现这一点,ScheduledThreadPoolExecutor
- 使用
DelayedWorkQueue改变了获取任务的具体实现 - 使用装饰模式包装原始任务,使得任务在满足
周期性的条件时,能够重新进入任务队列
作者按:JDK中的源码实现非常精彩,值得深读。gist
相信您已经对线程池的设计有了一定的理解,JDK1.8之后也在线程池中增加了Future相关的内容,本文不再继续展开。通过Executors中API的源码,应当已经掌握得到的线程池的特征。
意犹未尽之处
行文至此,内容已经非常冗长,但也不得不告一段落。 文中的部分内容,例如Future、AtomicInteger、CAS等内容,计划在本系列的其他文章中具体展开,文中亦颇多回避。 而DelayedQueue、线程池生命周期变化时的具体细节、线程池的调优等内容,均需要结合代码、场景具体分析,限于文章主题未能尽兴,读者闲暇之余若能将源码再阅读一二,定能有更大的收获。